How Google treats "allow" field in robots.txt
What is mean by Robots.txt: robots.txt is set of instructions for blocking the particular pages, folder, images, etc... Also, we can block the particular search engines by using robots.txt. like, Google, Bing, Yahoo, etc.
Allowing all the search engines and accessing all the files.
User-agent: *
Disallow:
Disallowing all the search engines and not accessible all the files.
User-agent: *
Disallow: /

Allowing all the search engines and accessing all the files.
User-agent: *
Disallow:
Disallowing all the search engines and not accessible all the files.
User-agent: *
Disallow: /
if we need to exclude all the files except few files, what we could do.
we have to use the disallow command for all the files, which need to be excluded. either files can be accessible by the search engines. Check the robotstxt.org advice here.
To exclude all files except one
This is currently a bit awkward, as there is no "Allow" field. The easy way is to put all files to be disallowed into a separate directory, say "stuff", and leave the one file in the level above this directory:
User-agent: *
Disallow: /~joe/stuff/
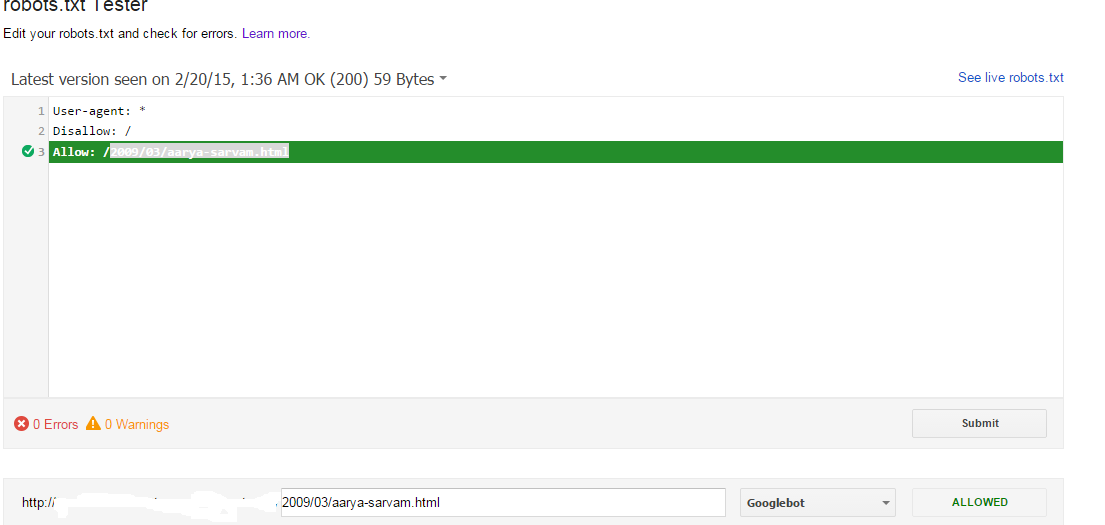
As per Google: To exclude all files except one:
User-agent: *
Disallow: /
Allow: /2009/03/aarya-sarvam.html
Google disallowing all the files except 2009/03/aarya-sarvam.html because of allow command. Google following all the disallow and allow in Robot.txt, Those allow method does not valid by robotstxt.org. But Google accepting the allow method and working according to that.
Check the visual screenshot here: Except file showing as Allowed in robots.txt Tester tool:
Checked another url in robots.txt Tester tool: It's showing as disallow
Robots.txt Changes: Before going to making a changes in the robots.txt. We need to test the changes via Robots.txt Tester tools.
Robots.txt Tester Tool: its online editor, so we can edit the text in robots.txt tester tool and we can check the changes before going to upload the robots.txt file in live server.
Test your robots.txt with the robots.txt Tester: https://support.google.com/webmasters/answer/6062598?hl=en

Comments